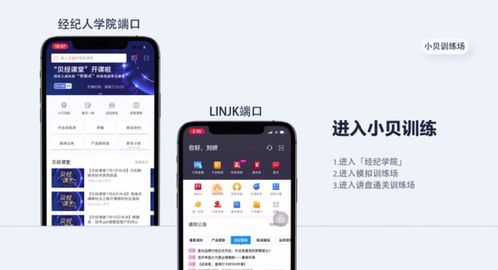
臻心實意 見吾初心丨走進「歸心工廠」,沉浸式探尋品質背后的秘密

在當今競爭激烈的房地產市場中,品質已成為開發商與購房者共同關注的核心。近日,我們有幸走進名為「歸心工廠」的房地產項目現場,通過沉浸式體驗,深入探尋其背后隱藏的品質秘密與房地產評估的關鍵要素。
「歸心工廠」不僅僅是一個建筑工地,更是一個融合匠心與科技的品質實驗室。從選材到施工,每一處細節都彰顯著開發商的“臻心實意”。例如,在建筑材料選擇上,項目團隊嚴格遵循環保與耐久性原則,采用高性能混凝土和節能玻璃,確保建筑在長期使用中保持穩定與舒適。同時,施工過程中引入了智能化監控系統,實時跟蹤工程進度與質量,避免人為誤差。這種對品質的極致追求,正是“見吾初心”的體現——不忘初心,只為交付一個安全、溫馨的家。
房地產評估在這一過程中扮演著至關重要的角色。評估不僅關注房屋的物理屬性,如結構安全、空間布局和裝修標準,還涉及項目的地理位置、周邊配套設施、市場趨勢及潛在增值空間。在「歸心工廠」的案例中,評估專家通過實地考察和數據模型分析,強調了其綠色建筑認證和社區規劃的優勢。例如,項目靠近地鐵站和學校,提升了生活便利性;而節能設計則降低了長期運維成本,這些因素共同構成了其較高的市場估值。評估結果顯示,「歸心工廠」不僅滿足了居住需求,更具備了投資潛力,這得益于開發商對品質的堅守與透明化的建設流程。
通過這次沉浸式探尋,我們深刻體會到,房地產的品質并非偶然,而是源于每一份真誠的初心與專業的評估體系。唯有將“臻心實意”融入每一個環節,才能打造出經得起時間考驗的居所。未來,隨著行業標準的提升,期待更多項目如「歸心工廠」般,以品質為基石,引領房地產市場的健康發展。
如若轉載,請注明出處:http://www.shuaigou.com.cn/product/15.html
更新時間:2026-06-19 11:13:15